یکی از عوامل مهم و تاثیر گذار در سئو سایت فایل robots است. ساخت این فایل و انجام تنظیمات آن از موارد مهم سئوی تکنیکال است. محتوای فایل robots.txt علاوه بر اینکه می تواند در بهبود یا بدتر شدن سئوی شما موثر باشد، در امنیت وب سایت شما نیز اثر گذار خواهد بود. در ادامه مطلب به اینکه فایل robots.txt چیست + روش ساخت فایل robots و مسایل مربوط به آن خواهیم پرداخت، با ما همراه باشید.
فایل robots.txt چه کاربردی دارد؟
فایلی است که با همین نام یعنی robots.txt و در روت هاست ایجاد می شود و به موتورهای جستجو اعلام می کند که به کدام صفحات سایت شما می تواند دسترسی داشته باشد و آن ها را crawl کند.
از مزایای استفاده از فایل robots.txt این است که باعث جلوگیری از افزایش لودینگ سایت توسط ربات های موتورهای جستجو می شود. البته این مساله به این معنی نیست که موتورهای جستجو نمی توانند دسترسی داشته باشند و نباید برای مخفی کردن یک صفحه از گوگل، از آن استفاده کرد.
برای جلوگیری از ایندکس شدن صفحات توسط موتورهای جستجو، باید از متاتگ no-index و یا password-protect کردن آن استفاده کرد.
تاثیر فایل robots.txt بر روی صفحات و فایل ها
در ادامه به ۲ نمونه از تاثیرات فایل robots.txt اشاره کرده ایم تا با توجه به آن به میزان اهمیت این فایل بیشتر پی ببرید.
۱- صفحات وب یا Web page ها
صفحات وب شامل صفحاتی می شود که موتورجستجو می تواند آن ها بخواند مثل HTML، PDF و فایل های از این دست. اگر فکر می کنید که نیازی به خواند این فایل ها توسط موتور های جستجو نیست یا صفحه دارای محتوای تکراری است، می توانید با فایل robots.txt از ربات ها بخواهید تا آن ها را نادیده بگیرند.

توجه: اگر صفحه وب شما با فایل robots.txt مسدود شده باشد، URL آن همچنان می تواند در نتایج جستجو ظاهر شود، اما نتیجه جستجو توضیحی نخواهد داشت. فایلهای تصویری، ویدیویی، PDF و سایر فایلهای غیر HTML از نتایج گوگل حذف خواهند شد. برای حذف کامل صفحه و لینک از نتایج جستجو، باید از روش دیگری که بالاتر گفتیم استفاده کنید.
۲- فایل های چندرسانه ای یا Media file ها
با کمک robots.txt می توانید مانع نمایش تصاویر، ویدئو ها و فایل های صوتی در نتایج موتورهای جستجوی مثل گوگل شود. پس کافیست تنظیمی اشتباه در این فایل داشته باشید!

۳- منابع سایت یا Resource file ها
منابع سایت شامل فایل های CSS و اسکریپت ها است که می توان به کمک این فایل آن ها را بلاک کرد. این کار را زمانی انجام دهید که مطمئن باشید لود نشدن این منابع تاثیر خاصی در درک ربات ها و تجزیه تحلیل آن ها نخواهد داشت.
اگر سایت شما فایل robots.txt را نداشته باشد چه اتفاقی میافتد؟
اگر وب سایت شما فایل robots را نداشته باشد، هر وقت ربات ها موتورهای جستجو به وب سایت شما برسند، تمام لینک و صفحات آن را Crawl و در نهایت ایندکس خواهند کرد.
این مساله می تواند در لودینگ سایت و همینطور امنیت سایت شما موثر باشد.
آموزش ساخت فایل robots.txt
همان طور که از اسم فایل مشخص است یک فایل متنی ساده است. در بخش فایل robots.txt چیست گفتیم این فایل در ریشه یا روت هاست ایجاد می شود بنابراین اگر آدرس سایت مثلا Elinweb.site باشد آنگاه لینک دسترسی به robots.txt به صورت elinweb.site/robots.txt خواهد بود.
پس برای ساخت فایل robots.txt آن وارد هاست شوید در پوشه روت هاست که معمولا با نام های public_html یا www هست شوید و فایل متنی ساده ای را با نام robots.txt ایجاد کنید.
پارامتر های فایل robots.txt
۱- User-agent : تعیین رباتی که می خواهید قوانین را برای آن مشخص کنید
۲- Disallow : فرمانی که به user-agent اعلام می کند یه URL هایی را نباید Crawl کند.
۳- Allow : فقط برای Googlebot کاربرد دارد. به Googlebot می گوید که به چه لینک هایی می تواند دسترسی داشته باشد حتی اگر قبلتر توسط فرمان Disallow ی اعمال شده روی Parent بلاک شده باشد.
۴- Crawl-delay : مدت زمانی که بر اساس ثانیه باید ربات منتظر بماند و بعد از آن مجاز است که صفحه را Crawl کند. این دستور توسط Googlebot نادیده گرفته می شود.
۵- Sitemap: برای اعلام لوکیشن sitemap های سایت به ربات ها استفاده می شود. در حال حاضر فقط ربات ها گوگل، بینگ، یاهو و Ask از آن پشتیبانی می کنند. آدرس sitemap باید به صورت کامل همراه با پروتکل http یا https آن نوشته شود.
نوشتن کامنت در فایل robots.txt
برای نوشتن کامنت در فایل robot.txt از علامت # یا هشتگ استفاده می شود.
تطبیق الگو یا Pattern Matching در robots.txt
با کمک دو کارکتر * و $ که از عبارت های با قاعده یا همان Regular Expressions استفاده می شود. کاربرد آن ها به این شرح است:
* کارکتری است که پذیرنده همه چیز است.
مثال : user-agent: * یعنی تمامی user-agent ها.
$ کارکتری که مشخص کننده پایان URL است.
مثال: Disallow: /*.xml$ یعنی جلوگیری از دسترسی ربات به همه URL هایی که هر اسمی دارند و به xml ختم می شوند. یعنی اگر فایلی باشد که آدرس آن به صورت elinweb/page/file.xml1 باشد برای ربات مجاز است.
نمونه دستورات کاربردی فایل robots.txt
جلوگیری از دسترسی همه ربات ها به کل سایت:
User-agent: *
Disallow: /اجازه دسترسی به همه ربات ها به کل سایت:
User-agent: *
Disallow: جلوگیری از ربات خاص برای دسترسی به یک url و صفحات زیرمجموعه:
User-agent: Googlebot
Disallow: /example-subfolder/توجه: اینکار باعث می شود ربات گوگل لینک های پس از /example-subfolder/ مثل /example-subfolder/a را نیز بررسی نکند.
جلوگیری از دسترسی ربات خاص به صفحه وب:
User-agent: Bingbot
Disallow: /example-subfolder/blocked-page.htmlگروه کردن user-agent ها:
اگر یک یا چند قانون رو بخواهیم برای دو یا چند ربات اعمال کنیم محتوای فایل robots.txt را باید اینگونه بنویسیم:
user-agent: a
user-agent: b
disallow: /دستورات بالا به ربات های a و b می گوید که مجاز به دیدن محتوای سایت نیستند.
گروه کردن قوانین:
اگر بخواهیم دو چند rule را برای یک ربات اعمال کنیم هر rule را زیر بعدی می نویسیم:
user-agent: googlebot-news
disallow: /fish
disallow: /shrimpدر مثال بالا ربات Googlebot-news مجاز به دیدن url های fish و shrimp و آدرس های مرتبط آن نیست.
یک اشتباه مهلک در robots.txt
دستور sitemap فقط توسط ۴ موتور جستجو قابل درک است و توسط سایر ربات های خزنده قابل درک نیست بنابراین دستورات زیر
User-agent: a
Sitemap: http://www.example.com/sitemap.xml
User-agent: b
disallow: /به صورت زیر در نظر گرفته می شود:
User-agent: a
User-agent: b
disallow: /و موتور جستجوی a و b هر دو از دسترسی به سایت منع می شوند. بنابراین حتما sitemap ها را در انتهای فایل robots.txt بنویسید.
نمونه فایل robots.txt
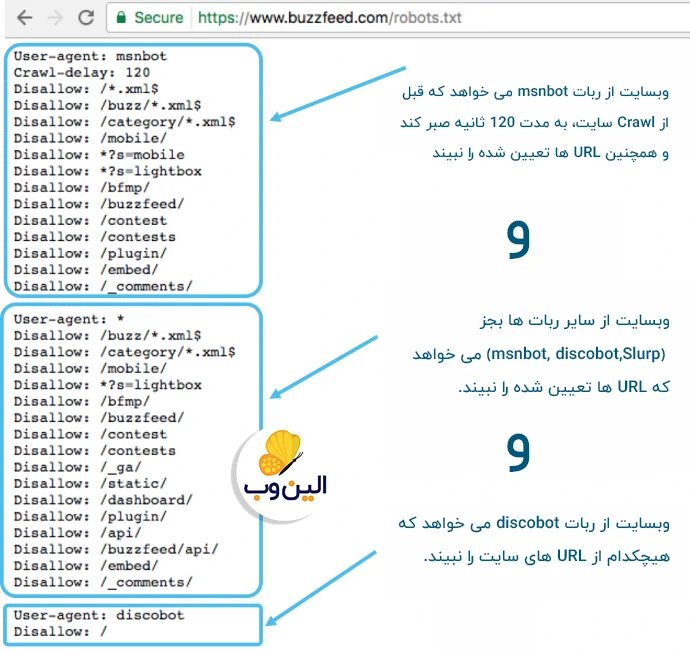
User-agent: msnbot
Crawl-delay: 120
Disallow: /*.xml$
Disallow: /buzz/*.xml$
User-agent: *
Disallow: /buzz/*.xml$
Disallow: /category/*.xml$
Disallow: /search/
User-agent: discobot
Disallow: /
User-agent: dotbot
Disallow: /
User-agent: Slurp
Crawl-delay: 4
Sitemap: https://www.buzzfeed.com/sitemap/asis.xml
Sitemap: https://www.buzzfeed.com/sitemap/buzzfeed.xml
Sitemap: https://www.buzzfeed.com/sitemap/tasty.xml
Sitemap: https://www.buzzfeed.com/sitemap/video.xml
تطبیق URL ها بر اساس مقادیر داده شده در robots.txt
در آپدیت بعدی
اولیت دستورات در فایل robots.txt
در آپدیت بعدی
محدودیت های فایل robots.txt
- حدکثر حجم فایل ۵۰۰ کیلو بایت
در حال حاضر گوگل حدکثر سایز مجاز فایل robots.txt را ۵۰۰ کیلو بایت می داند و محتویات که بعد از این سایز قرار میگیرند را نادیده می گیرد.
با دستورات، قوانین، بایدها و نباید های ساخت robots.txt و کاربردی ترین مثال های آن آشنا شدیم و در نهایت به اهمیت و جایگاه robots.txt در سئو و امنیت پی بردیم.
- عدم پشتیبانی همه موتورهای جستجو از قوانین robots.txt
قوانین و Rule های فایل robots.txt ممکن است توسط همه موتورهای جستجو پشتیبانی نشود. و نمی تواند همه موتورهای جستجو را وادار به پیروی کند.
- برداشت متفاوت سایر موتورهای جستجو از syntax
هر موتور جستجویی ممکن است برداشت خاص خودش را robots.txt داشته باشد و برخی از syntax ها و دستورات فایل robots.txt را متوجه نشوند.
- صفحه بلاک شده در robots.txt هنوز هم قابل ایندکس است!
ممکن است صفحه ای را توسط فایل robots.txt بلاک کرده باشید ولی لینک آن در وب سایت های دیگر قرار گرفته باشد و توسط موتورهای جستجو Crawl و ایندکس شود و در نتایج جستجو نمایان شود!
دیگر نکات مهم در ساخت فایل robots.txt
- به کوچکی و بزرگی حروف حساس است. مثلا فایل Robots نامعتبر است.
- فایل robots در مسیر هایی غیر از روت سایت مثل Example.com/page/robots.txt نامعتبر است.
- هر سابدامنه ای باید فایل robotsخودش را داشته باشد.
- بهتر است که هر sitemap مربوط به سایت های چند زبانه حتما در انتهای robots.txt قرارداده شود.
- گوگل فایل robots را به مدت ۲۴ ساعت cache می کند.
تاثیر فایل robots.txt در سئو
- جلوگیری از ظاهر شدن محتوای تکراری در SERP . توجه داشته باشید که متا روبات ها اغلب انتخاب بهتری برای این کار هستند.
- خصوصی نگه داشتن بخش های کامل یک وب سایت (به عنوان مثال، سایت مرحله بندی تیم مهندسی شما)
- جلوگیری از نمایش صفحات نتایج جستجوی داخلی در SERP عمومی
- تعیین مکان Sitemap
- جلوگیری از ایندکس کردن فایل های خاص در وب سایت شما مثل تصاویر، PDF و غیره) توسط موتورهای جستجو.
- تعیین تأخیر Crawl برای جلوگیری از لود بیش از حد سرورها در زمان بارگیری همزمان چند فایل محتوا توسط خزنده ها
در این رابطه بیشتر بدانید: سئو چیست؟
تاثیر تنظیمات اشتباه فایل robots.txt
- می تواند باعث حذف وب سایت شما از نتایج موتورهای جستجو شود.
- می تواند باعث حذف بخشی از محتوای وب سایت شما مثل تصاویر و ویدئو ها در نتایج جستجو شود
- عدم استفاده از آن می تواند باعث افزایش لود سرور شود.
- درصورتی که منابع سایت مثل اسکریپت ها و فایل های CSS را بلاک کرده باشید با خطای Mobile Not Friendly روبرو شوید و در نهایت صفحه شما ایندکس نشود.
- در صورتی که لینک فایل ها حیاتی و امنیتی مثل صفحه لاگین یا دایرکتورهای حاوی فایل ها حساس را در robots.txt آورده باشید، به راحتی توسط هکر ها قابل شناسایی خواهد بود.
جمع بندی
امیدواریم این آموزش برای شما مفید باشد. حالا که یادگرفتید فایل robots.txt چیست به سوال زیر جواب بدید:
سوال: به نظر شما ربات Mediapartners-Google می تواند به محتوای سایت دسترسی داشته باشد یا خیر؟
User-agent: *
Disallow: /user/*
Disallow: /invitations/*
Disallow: /api/*
#Adsense crawler
User-agent: Mediapartners-Google
Disallow:
جواب سوال را در بخش کامنت ها با دیگر مخاطبین الین وب به اشتراک بگذارید، چنانچه پاسخ شما صحیح نباشد حتما پیرو آن توضیحاتی خواهیم داد.